Complete Epics
This section includes Jira cards that are linked to an Epic, but the Epic itself is not linked to any Feature. These epics were completed when this image was assembled
An epic we can duplicate for each release to ensure we have a place to catch things we ought to be doing regularly but can tend to fall by the wayside.
Update console from Cypress 6.0.0 to 8.5.0. Changes that impact us:
- cypress run is headless by default
- cy.intercept URL matching is more strict
- Uncaught exception and unhandled promise rejection checks are more strict
https://docs.cypress.io/guides/references/migration-guide#Migrating-to-Cypress-8-0
As an adopter of the @openshift-console/dynamic-plugin-sdk I want to easily integrate into my development pipeline so that I can extend the OCP console.
Trying to pull in the dynamic-plugin-sdk into ACM is proving to be problematic. We would have to move to older dependencies. Integrating with webpack and typescript requires a very specific setup.
The dynamic-plugin-sdk has only really been used internally by OCP and is strongly tied to the setup and dependencies of OCP. For the dynamic-plugin-sdk to be externally consumable by adopters, it should be as easy to use as other webpack plugins such as HtmlWebpackPlugin or CompressionPlugin.
Acceptance Criteria
- Uses up to date dependencies - not tied to specific versions OCP console uses
- Includes it's own dependencies - does not require adopters to include those dependencies
- The dynamic demo plugin should be updated to use newer dependencies and use the plugin without a bunch of tweaks to tsconfig paths.
Currently
- requires old dependencies
- ts-node 5.0.1 → 10.2.1
The console has many instances of old variables, $grid-float-breakpoint and $grid-gutter-width, controlling margins/padding and responsive breakpoints throughout the Admin and Dev Console. These do not provide spacing and behaviors consistent with Patternfly components which use their own variables, $pf-global-gutter-md, $pf-global-gutter, and $pf-global-breakpoint-{size}. By replacing these, the intent it to bring the console closer to a pure Patternfly structure and behavior, requiring less overrides and customizations.
Update webpack to the latest 4.x and update webpack loaders. This will help prepare us to move to webpack 5.
Epic Goal
- Improve CI testing of the image registry components.
Why is this important?
- The image registry, image API and the image pruner had a lot of tests removed during transition 4.0. This may make the platform less stable and/or slow down the team.
Scenarios
- ...
Acceptance Criteria
- CI - tests should be more stable and have broader coverage
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
In the image-registry, we have packages origin-common and kubernetes-common. The problem is that this code doesn't get updates. We can replace them with more supported library-go.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- ...
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story
As a developer using Jenkins to build my application
I want to use the base Jenkins agent image as a sidecar in my PodTemplate
So that I can use any s2i builder image in my Jenkins pipelines
Acceptance Criteria
- Provide new Kubernetes Plugin Pod Templates which uses the sidecar pattern for NodeJS and Maven.
- Add documentation on how to use the new pod template in a Jenkinsfile (need to specify the container where the build occurs).
- Add documentation on how developers can provide an inline pod template within a Jenkinsfile. Documentation should have the following formats:
- New YAML declarative format
- Deprecated Groovy format
- Existing pipelines that use the default Kubernetes Plugin Pod Templates do not break.
- End to end testing (for client or sync plugin) verifies that the new pod templates work.
QE Impact
QE will need to verify that the new pod templates can successfully execute a JenkinsPipeline build.
Docs Impact
Documentation needs to be updated to explain how to use the new template.
PX Impact
Unclear if we need new CEE/PX materials beyond doc updates.
Notes
We currently have built-in pod templates for NodeJS and Maven, which use specialized agent images with NodeJS/Maven image.
Blog post here outlines the process: https://developers.redhat.com/blog/2020/06/04/an-easier-way-to-create-custom-jenkins-containers/
The Groovy style of declaring in-line pod templates is deprecated in favor of a YAML-style format.
Existing documentation for the Jenkin pod templates: https://docs.openshift.com/container-platform/4.9/openshift_images/using_images/images-other-jenkins.html#images-other-jenkins-config-kubernetes_images-other-jenkins
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
Epic Goal
- As a CFE team, we would like to enable query logging for all Prometheus read paths
- As part of this, we would like to enable audit & query logging for Prometheus Adapter(aggregated server audit log), Prometheus(query log) and ThanosQuerier(query log)
Why is this important?
- This would help all parties(customers, app-sres, CCX, monitoring team,..) to debug an overloaded Prometheus instance.
Scenarios
- When a customer faces a high cpu consumption in any of the Prometheus instance, they can enable audit logging in Prometheus Adapter to see which component is calling metrics API
- When a customer faces a high cpu consumption in any of the Prometheus instance, they can enable query logging in all Prometheus instances(PM & UWM) and ThanosQuerier to see which query is frequently executed
- https://bugzilla.redhat.com/show_bug.cgi?id=1982302
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Prometheus Adapter audit logs must be enabled by default
- Prometheus Adapter audit logs must be preserved after each CI run
Open questions::
- Should we enable ThanosRuler query logs?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
After investigating a complex Bugzilla involving many applications making queries to prometheus-adapter, we've noticed that we were lacking insights on the requests made to prometheus-adapter. To have such information for an aggregated API, the best would be to have audit logs for prometheus-adapter. This wasn't configurable before, but with https://github.com/kubernetes-sigs/custom-metrics-apiserver/pull/92, upstream users should now be able to configure it.
Since this would greatly help in investigating prometheus-adapter Bugzilla in the future, it would be great if we allowed OpenShift users to configure the audit logs so that they could provide them to us.
Note for the assignee: as of the time of the creation of this ticket, the upstream PR hasn't been merged in custom-metrics-apiserver and thus wasn't synced in prometheus-adapter. So we will have to wait a bit before starting looking into this ticket.
DoD:
- Allow OpenShift users to configure audit logs for prometheus-adapter
- Integrate with must-gather
- Document how to configure audit logs in the official OpenShift documentation
- Upstream jsonnet patch that enables this feature through a configuration
The console requires to know the network type capabilities to show/hide some Network Policy form fields.
As a result of https://issues.redhat.com/browse/NETOBSERV-27, this logic is implemented as a features document inside the console code. The console fetches the network type from the network operator and checks the supported features towards this document.
However, this limits the feature to admin users, as other logged-in users do not have permissions to fetch the network type.
This task aims to modify the current Cluster Network Operator to expose the network capabilities as an `sdn-public` Config Map, writeable only by the SDN, readable by any `system:authenticated` user.
Enhancement Proposal PR: https://github.com/openshift/enhancements/pull/875
We want to configure 'default' and 'allowed' values in validation webhook for Guest Accelerators field in GCPProviderSpec. Also revendor it to include newly added Guest Accelerators field.
This can be done after https://github.com/openshift/cluster-api-provider-gcp/pull/172 is merged.
DoD:
- Make sure that validations return errors on issues with GPU configuration
- Ensure the unit tests for the webhooks are updated
Description:
Openshift on RHV is composed of the following subproject the team maintains:
- installer
- cluster-api-provider-ovirt
- ovirt-csi-driver
- ovirt-csi-driver-operator
- terraform-provider-ovirt
Each of those projects currently uses the generated oVirt API project go-ovirt.
This leads to a number of issues:
- Duplicated code between the subprojects: Since the go-ovirt is a thin layer around the API then a lot of the code which interacts with oVirt is duplicated between the projects, which leads to all the classic duplication problems such as maintaining the project, lack of clear conventions, and so on.
- Bad error handling and unclear errors:
- Since the go-ovirt is a thin layer there is a lot of error handling and checking which needs to be done, since a lot of the times it looks like a certain error should be ignored, it is never checked which could lead to unexpected situations.
- Since the errors which are returned from the oVirt Engine are sometimes unclear, when we return those errors to the users or log them is hard to understand what is the actual issue.
- Lack of retries: sometimes an operation can take some time due to some condition that needs to be met, or an operation can fail due to infrastructure issues, the go-ovirt library doesn't contain any retry logic which means each client needs to implement its own retry logic which is not done at the moment and will cause more duplicated code.
- Poor logging: The current go-ovirt library doesn't log anything, and all the logs come from the subprojects, this leads to:
- Inconsistent logging between the projects.
- Lack of logs.
- Almost no test coverage:
- It's very hard to mock and write tests with go-ovirt since there are so many calls, but will be much easier to mock and write tests with go-ovirt-clent.
- go-ovirt only has rudimentary tests.
Then came go-ovirt-client, go-ovirt-client-log, go-ovirt-client-log-klog and k8sOVirtCredentialsMonitor to the rescue!
The go-ovirt-client is a wrapper around the go-ovirt which contains all the error handling/retry logic/logs/tests needed to provide a decent user experience and an easy-to-use API to the oVirt engine.
go-ovirt-client-log is a library to unify the logging logic between the projects, it is used by go-ovirt-client and should be used by all the sub-projects.
go-ovirt-client-log-klog is a companion library to go-ovirt-client-log enabling logging via the Kubernetes "klog" facility.
k8sOVirtCredentialsMonitor is a utility for monitoring the oVirt credentials secret, which will automatically update the ovirt credentials is they are changed.
We aim to move all projects which are using the go-ovirt to use go-ovirt-client, go-ovirt-client-log and k8sOVirtCredentialsMonitor instead.
Benefits for the eng:
- Possible to write unit tests.
- Easier to maintain since less code duplication - reduce the amount of code.
- Test coverage exists on the ovirt-client as well.
- No(Less) bugs regarding operations that needed a retry or polling logic.
- Solves a number of existing bugs
Benefits for the customers:
- Clearer error messages and logs.
- Fewer bugs.
Acceptance criteria:
- All sub-projects are not using go-ovirt directly - at least 90% of the calls to go-ovirt should be migrated to go-ovirt-client.
- All sub-projects should use the corresponding go-ovirt-client-log for logging.
- All csi-driver and cluster provide use k8sOVirtCredentialsMonitor.
- CI tests are green for all components.
How to test:
- QE regression - make sure all flows are still working.
- Green CI on all jobs.
- Keep an eye out for log messages that might confuse customers.
Description:
- Identify all the communication between ovirt-csi-driver and the go-ovirt.
- Port all the logic to go-ovirt-client.
- Port all calls on ovirt-csi-driver to go-ovirt-client.
Acceptance:
ovirt-csi-driver uses go-ovirt-client for 95% percent of all oVirt related logic.
T-shirt size: M
Goal:
Provide an easy and successful experience for front end developers to build and deploy their applications
Why is it important?
Currently, the front end dev experience is not positive. It's much easier for them to use other platforms. Improving the front end dev experience will enable us to gain more marketshare
Use cases:
- Need to be able to override the npm command when using Node Builder Image
- Need to expose target port
- Need access to the URL to access my application
Although we provide the ability for 2 & 3 today, the current journey does not match with the mental model of the front end developer
Acceptance criteria:
- When importing an app, I should be able to easily provide the npm build and run commands
- When opting in to create a route, the target port should be exposed without having to open any Advanced Options
- After importing my app, if a route is exposed, I should be able to access/copy that URL
Dependencies (External/Internal):
Design Artifacts:
Desired UX experience
- enable user to provide the *Build Command* when Node Builder image is being used
- enable user to provide the *Run Command* when Node Builder image is being used
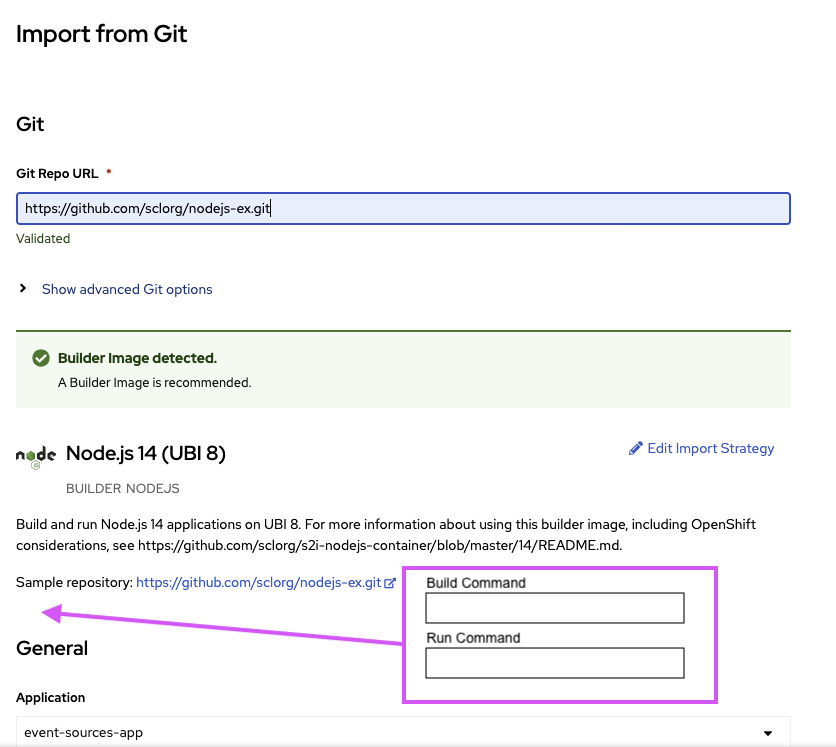
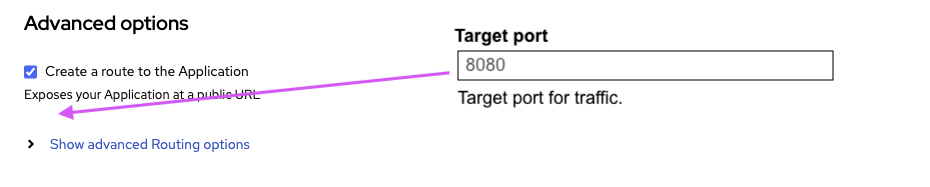
- expose the Target Port under the *Create a route to the Application *rather than inside Show advanced Routing options
- NEED TO FINALIZE HOW TO PROVIDE THE ROUTE TO EASILY COPY – Inline Notification maybe? As well as side panel?
Note:
Description
As a user, I want have the option to add additional labels to a Route, as I could do in OCP3. See RFE-622
The additional labels should only be added to the route, not the service or other components. The advanced option "Labels" should not be touched and these labels are added to all components.
As an small additional we should also show always the "Target port" since it also defines the Service port and to make this more clear, the "Target port" should be shown before the "Create a route to the Application" checkbox.
Acceptance Criteria
The following changes should be applied to the Import flow (from Git, from Container, ...) and to the Edit page as well:
- Move the option "Target port" before the checkbox "Create a route to the Application" and do not hide the "Target port" when the checkbox is disabled
- Add a new "Additional route labels" option, with a label input field to the "Advanced Routing options"
- Save (Import) and update (Edit) the labels to the Route resource. When editing a Deployment with a Route the route labels should not show the shared labels.
Additional Details:
Problem:
This epic is mainly focused on the 4.10 Release QE activities
Goal:
1. Identify the scenarios for automation
2. Segregate the test Scenarios into smoke, Regression and other user stories
a. Update the https://docs.jboss.org/display/ODC/Automation+Status+Report
3. Align with layered operator teams for updating scripts
3. Work closely with dev team for epic automation
4. Create the automation scripts using cypress
5. Implement CI for nightly builds
6. Execute scripts on sprint basis
Why is it important?
To the track the QE progress at one place in 4.10 Release Confluence page
Use cases:
- <case>
Acceptance criteria:
- <criteria>
Dependencies (External/Internal):
Design Artifacts:
Exploration:
Note:
There are different code spots which maps the old action items "From Git", "From Dockerfile" and "From Devfile" to the new action "Import from Git".
We should avoid mapping different strings to the new version and instead update our tests so that the feature and page object files matches the latest frontend code.
Code areas I found are marked with
// TODO (ODC-6455): Tests should use latest UI labels like "Import from Git" instead of mapping strings